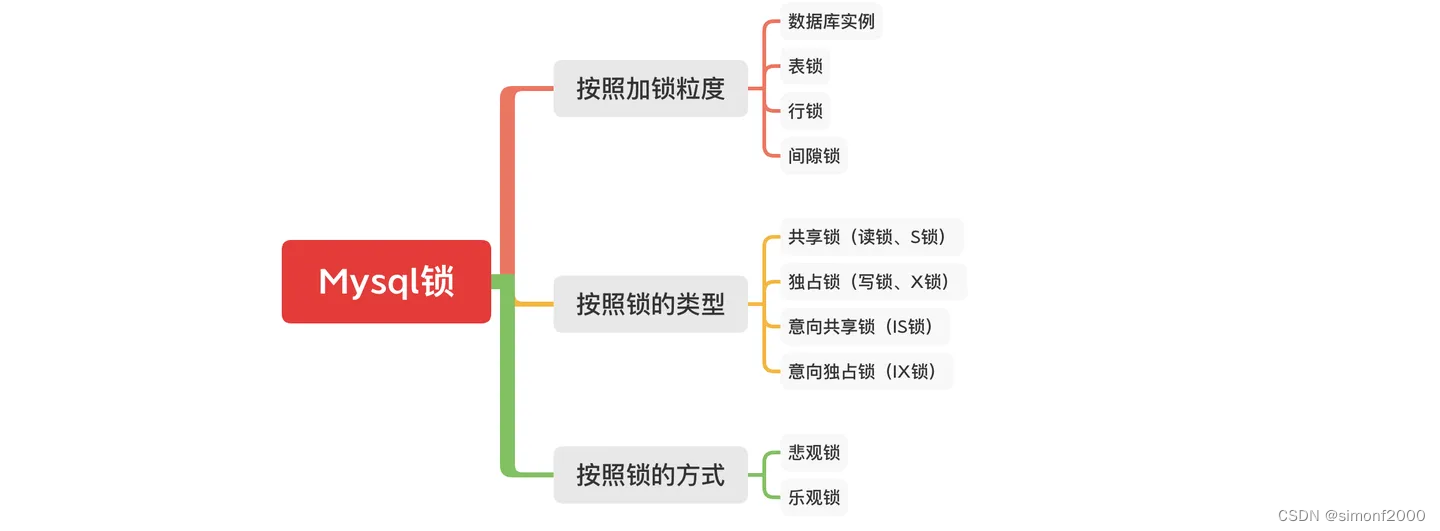
for update仅适用于InnoDB,且必须在事务块(BEGIN/COMMIT)中才能生效。在进行事务操作时,通过“for update”语句,MySQL会对查询结果集中每行数据都添加排他锁,其他线程对该记录的更新与删除操作都会阻塞。排他锁包含行锁、表锁。
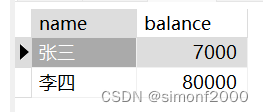
验证排他锁,设计一张表:
1 2 3 4 5 6 7 8 9 10 11 12
/* 开启事务1 */ BEGIN; /* 查询name为张三的数据并加上排他锁 */ SELECT * FROM test WHERE name = '张三' FOR UPDATE; /* 延迟10秒执行 */ SELECT SLEEP(10); /* 尝试修改 name = '张三' 的数据 */ UPDATE test SET balance = 5000 WHERE name = '张三'; /* 延迟15秒执行 */ SELECT SLEEP(15); /* 提交事务1 */ COMMIT;
开启事务1的执行过程如下:
同时开启事务二:
1 2 3 4 5 6
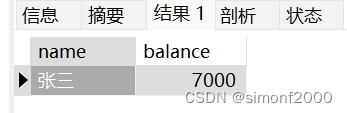
/* 开启事务2 */ BEGIN; /* 普通查询name = '张三'的数据 */ SELECT * FROM test WHERE name = '张三'; /* 提交事务2 */ COMMIT;
/* 开启事务1 */ BEGIN; /* 查询name为张三的数据并加上排他锁 */ SELECT * FROM test WHERE name = '张三' FOR UPDATE; /* 延迟10秒执行 */ SELECT SLEEP(10); /* 尝试修改 name = '张三' 的数据 */ UPDATE test SET balance = 5000 WHERE name = '张三'; /* 延迟15秒执行 */ SELECT SLEEP(15); /* 提交事务1 */ COMMIT;
事务二对张三的余额进行修改操作
1 2 3 4 5 6
/* 开启事务2 */ BEGIN; /* 尝试修改 name = '张三' 的数据 */ UPDATE test SET balance = 2000 WHERE name = '张三'; /* 提交事务2 */ COMMIT;